在資料分析和機器學習中,scikit-learn(簡稱 sklearn)是 Python 中最強大、最受歡迎的套件之一。它提供了許多便捷的工具來進行數據預處理、模型訓練和評估,特別適合用來快速建立機器學習模型。
sklearn 提供了幾個經典的資料集供我們練習使用,這些資料集涵蓋了分類、回歸等多種問題類型。我們可以透過簡單的指令來讀取這些資料。
以下是幾個常見的內建資料集:
我們可以使用 sklearn.datasets 模組來呼叫這些內建的資料集,並進行簡單的探索。讓我們來看一下如何使用這些資料集。
如果你使用的是 Google Colab,sklearn 已經預先安裝好了,你可以直接使用。如果你在本地環境中使用,則需要先安裝它:
pip install scikit-learn
點取+code的按鈕,可以新增code
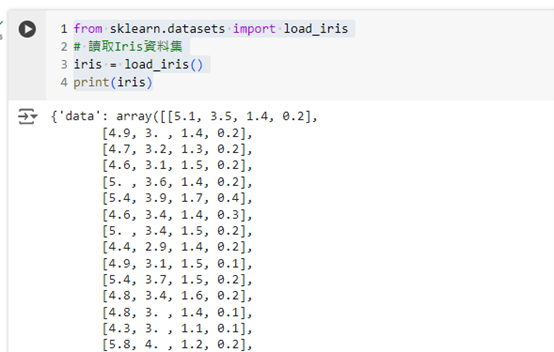
from sklearn.datasets import load_iris
# 讀取 Iris 資料集
iris = load_iris()
print(iris)
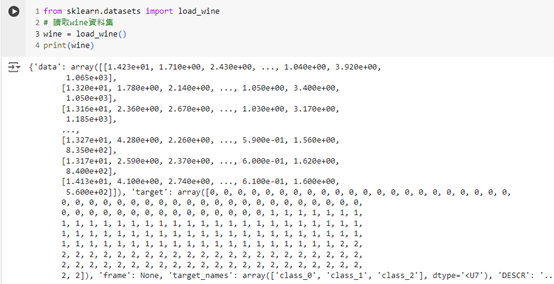
from sklearn.datasets import load_wine
# 讀取 Wine 資料集
wine = load_wine()
print(wine)
知道sklearn的套件裡面資料之後,明天我會以iris為例子來說明如何將資料輸出成CSV檔案。
如果有任何問題,歡迎私訊我的IG
我的IG


 iThome鐵人賽
iThome鐵人賽